
[Data Science] Embedding和向量資料庫系列-1:Embedding是什麼?
前言
2022年底,ChatGPT橫空出世,為整個世界帶來又一次的AI熱潮,短短幾個月間,各式各樣的嘗試與應用隨之出現。Open AI 這次投下的震撼彈,也逼著其他科技巨頭們紛紛跟著出牌,一時間整個AI界百花齊放,不只是LLM (Large Language Model,大型語言模型)的各種花式應用,其他 AIGC (AI Generated Content)的模型與討論也跟著大量出現。
隨著大量對LLM的嘗試與體驗後,人們開始日漸理解LLM生成的品質與限制。大家開始思考,如果想將LLM應用在自己的商業情境中,該怎麼實現讓LLM "依照指定或有限範圍中的資料或知識"來回答呢? 於是,向量資料庫就在這樣的背景下迎來崛起,跟著成為熱門的討論話題,就讓我們來看看LLM接上向量資料庫這個"外接的大腦"到底是怎麼一回事吧!
本篇文章包含三個段落,主要想帶大家理解向量嵌入的基本概念:
- Embedding是模型理解世界的方式
- 簡單理解Embedding的概念
- 為什麼需要使用Embedding? 它解決了什麼問題?
Vector Embedding 向量嵌入
在談語言模型與向量資料庫之前,得先了解到底什麼是Embedding (嵌入) 。嵌入,嵌讀音ㄑㄧㄢ,在數學上指的是一個數學結構經映射包含到另一個結構中,而在ML(Machine Learning,機器學習)、DL(Deep Learning,深度學習)的領域,則是指將實體(entity)高維離散的特徵映射到相對低維的連續向量空間中。在不同ML/DL 模型中,依照不同的情境或任務,我們可以看到各式各樣不同實體的Embedding,比如: User Embedding、Item Embedding、Graph Embedding、Word Embedding …等。
Embedding是模型理解世界的方式
Embedding的概念其實是包含在Manifold Hypothesis (流形假設)之中。Manifold Hypothesis主要的觀點是我們平常觀察到的數據其實是由一個低維manifold映射到高維空間上的,然而在高維空間中,一些數據在某些層面上其實會產生維度的冗餘,實際上只需要比較低的維度就能做唯一表示,也就是某個數據集合,在一個局部的空間條件下,可以用較少的維度表示。以現實世界的空間來說 ,地球是一個在三維空間的橢圓球,但是如果只考慮其中一小部分的事情,像是臺北101到中正紀念堂的路線,其實我可以用二維的平面地圖提供方位資訊。一個理想的數學上的球面在足夠小的區域上的特性就像一個平面,這表明它是一個流形。
而在ML/DL模型中,套用Manifold Hypothesis中Embedding的概念,把它作為複雜實體轉換成相對低維稠密向量的表達方式。通常,Embedding會是中間的產物,再針對不同任務,串接不同的下游模型完成任務。模型訓練的過程就是從大量的輸入特徵中,找出特徵間複雜的交互關係,最終得以輸出結果。這樣的過程,其實可以理解成試圖讓模型模擬人類思考的方式。

舉例來說,當我們看到一顆蘋果,其實是視神經接受到當下光線進入的強度,並將這些訊號傳送到大腦,並經由大腦中上千億的神經元連結形成的網絡,最終得到解釋:我看到了蘋果。
在這個判斷 "看到蘋果"的過程中,大腦真正解讀並非眼睛看到的影像,而是視覺皮層輸出的神經訊號表示。
ML/DL模型也同樣如此,雖然模型看起來像是能藉由輸入一段文字、一張圖片或是一段行為,最後可以輸出預測結果,然而實際上要讓模型"看懂"這些輸入,同樣也得經過轉換,成為模型能理解的樣子。
Embedding也可以想成是向量化(Vectorize)的結果,也就是將資料映射到空間,將其變成一串數字組成的向量來讓模型理解,而Embedding的目標,就是找到一組合適的向量來表達實體的特徵。
綜合來說,Embedding的主要用途如下:
1.將複雜、高維離散的實體,映射到相對低維稠密的連續向量空間。
2.Embedding的目標是表達實體的特徵,包含概念與關係的相似與相異,並且能幫助模型訓練。
衡量模型Embedding好壞的幾個重點:
- 經過映射轉換後的維度是否合適。
- Embedding能否在指定的模型目標下,充分表達實體。
- 在產生的Embedding空間中,相似的實體能在空間中接近,相異的會在空間中距離較遠。
藉由降維視覺化,我們可以利用Embedding Projector看看Embedding在空間中投影的感覺:


-可以是一個商品、一串文字、一段行為、一張圖片、 一個序列
簡單理解Embedding的概念
讓我們來看一個人類思考的例子來類比:
假設今天有五位籃球員,要在其中選出最適合球隊的後衛人選,考量人選的流程可能如下:

球探在看完每個球員的十場比賽以及賽後統計數字後,可能會做出如下的球員分析評分報告:
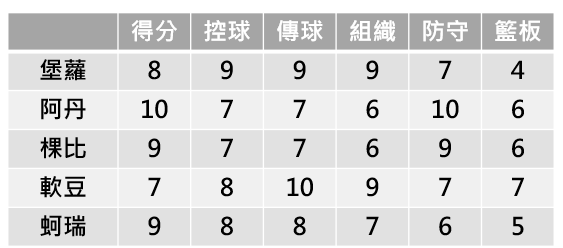
這樣子從原始複雜的資料(球賽內容)到量化的資料(統計數據)的方式,就好比資料的收集。而從量化的統計數據轉換成球員分析評分報告,是球探用他的知識來衡量不同面相(維度)球員的評分,這個轉換可以廣義的視為是向量化成embedding的過程。
這個"轉換成球員評分報告"的過程,對應到模型的流程上可以是一個Embedding model或layer,而"選出適合球隊的人選",就像是下游模型或任務。如果最後的球員分析評分報告,可以讓人真的選到最適合球隊的後衛人選,同時還能夠從這些Embedding知道阿丹跟棵比是很相近的球員。那這樣的Embedding可能對於"選出最適合球隊的人選"的這個任務就是一組合適的Embedding,因為它能達到最終選球員的目標,同時也能很好的表示球員相似/相異的特性。
為什麼需要使用Embedding? 它解決了什麼問題?
經過前面的例子,相信大家應該都能理解Embedding的概念。不過,大家這時可能會想,這樣看來簡單的轉換,不像是解決了什麼困難的問題,為什麼會經常現在ML/DL模型中出現呢?
一切都要從NLP(Natural Language Processing,自然語言處理) 模型應用Embedding開始說起:
隨著運算能力穩定增加,ML/DL開始快速發展,我們開始試圖讓模型學習人類的語言。然而面對成千上萬的字詞,以及非常複雜的語意關係,該如何將語言轉換成向量呢?
我們來看一個例子,假設今天一句話 "我愛資料科學",依照字詞的意思,我們可以將其拆成:
我、愛、資料、科學四個詞。如果今天總共只有四個詞,想要用向量表達的話,最簡單的做法就是one-hot encoding (獨熱編碼)。意思是在共有n個實體的條件下,用一個n維向量,但每個向量都只有一個1來表示,就像下面這樣:

然而,今天若是有成千上萬的字詞,若是用one-hot表示,我們會得到很多個很多0的向量,比如一萬個詞,就會有一萬個有9,999個0的向量,這樣很稀疏的表示其實不利於模型使用。同時,大家如果還記得前面講到好的embedding要能表達相似與相異性,這樣的向量很難很好的表達複雜的語意概念。於是,後續就發展出不同處理文本的方式,來學習複雜的語意關係。(雖然這邊我們用詞來舉例,不過實務上詞的組合可能會比字來的更多,所以通常會以字來實作。)
在這樣的背景下,語言模型利用Embedding的概念後快速發展。word2vec的出現帶動大量word embedding 模型發展,像是ELMO、GPT、BERT等,之後再來細談這些模型的發展歷史。
NLP任務中加入Embedding概念,解決了自然語言複雜的語境和語意關係的表示方式,Embedding雖然對於人類來說看起來就像一串數字,卻是模型理解世界的方式,我們就可以藉由這些包含意涵的向量來應用。
所以Embedding到底解決了什麼問題?
Embedding將關係複雜的自然語言進行轉換,使其能夠用向量來表達字詞的關係,而模型就能進一步利用這樣字詞向量來完成不同的自然語言任務。
小結
本篇文章是"Embedding和向量資料庫"系列文章的Embedding篇,主要帶大家認識Embedding的概念。
在這邊整理幾個重要的概念:
- Embedding是將實體高維離散的特徵映射到相對低維的連續向量空間中的表示方式。
- 藉由轉換,Embedding讓模型試圖理解現實中不同的複雜概念。
- 好的Embedding在向量空間中可以表達實體的相似與相異關係。
- Embedding解決了原先自然語言稀疏的表達方式,讓模型可以完成複雜的自然語言任務。


