
[Data Science] Embedding和向量資料庫系列-2:Embedding實作與相似度計算
前言
上回,在Embedding和向量資料庫系列-1:Embedding是什麼?介紹了Embedding的幾個基本概念,講述了Embedding產生的方式以及其可表達實體的相似與相異關係的特性。這次,本文將利用Sentence-BERT實作範例,帶大家認識如何幫文本產生Embedding,並且利用相似度的計算來完成一些情境的應用。
語言模型
當我們想要幫文本產生Embedding,可能會遇到一系列的問題;如,從眾多語言模型中,應該選擇哪個開始下手? 模型是否可以直接使用? 模型可以從哪些途徑取得或訓練?
首先,大家可以很簡單的試想一下,如果Embedding可以來表示數量龐大的文字和複雜的語意關係,那過程中使用和產出Embedding的語言模型,想必相對的需要大量高品質且還蓋廣泛主題類型的文本資料集作為訓練基礎。 而大量的訓練資料也意味著需要強大的運算資源和大量運算時間。大家可能有聽過由Google的BERT衍生的各種模型,或是最近期熱度很高的OpenAI的GPT系列模型,這些都是耗費大量成本訓練出來的模型。而這些已經經過大量資料訓練的模型,我們會稱為預訓練模型(pre-trained model)或是基礎模型(foundation model)。通常,這些模型經過訓練後已經具備一定的能力,就像是有人已經"預訓練"好的"基礎",直接使用就有一定的效果,只要再針對需求任務進行調整或設計就可以有更好的效果。
Hugging Face Hub
如果想找一些預訓練模型來測試可以去哪邊找呢? Hugging Face會是一個好選擇。Hugging Face是一個擁有12萬個模型、2萬個資料集以及5萬個demo應用的平台,並且全都是公開與開源的。開發者可以依照不同任務,從上面找到許多預訓練的模型來使用。從下圖我們可以看到, Hugging Face在將模型依照任務、library、資料集、語言、授權條款等進行分類。我們可以很簡單的篩選出自己需要的模型。

在模型詳細資訊的頁面,有些模型還有提供Hosted inference API讓大家測試效果。下圖是中研院、聯發創新基地以及國教院合作發布的 bloom-1b1-zh,是一個繁體中文訓練的生成式語言模型。可以看到右邊的文字框demo了他的文本生成效果。

語意相似度 - Sentence-BERT (SBERT)
今天,我們會介紹語句相似度(Sentence Similarity)任務,並選擇效果良好且熱門的Sentence-BERT來做示範,從Hugging Face的Sentence Similarity類別中,可以看到熱門的前幾名幾乎都是sentence-transformers提供的模型。

SBERT簡介
SBERT利用孿生網路(siamense networks)來作文本語意相似度的訓練,SBERT模型的兩個子網絡都採用BERT模型,並且模型共享參數。當兩個句子輸入同時被分別輸入到BERT網路中後,兩個子網路會分別輸出代表兩個句子的向量,最後計算它們之間的相似度。文本語意相似度可以衍生很多不同的應用情境,比如主題分類、意圖理解、文本檢索等,後面我們會舉例來示範。

要使用SBERT,我們必須先安裝sentence-transformers套件,可以參考官方文件,如果要使用GPU加速,必須先安裝pytorch與對應的CUDA版本。
使用 pip安裝:
pip install -U sentence-transformers
使用 conda安裝:
conda install -c conda-forge sentence-transformers
文本相似度計算
我們參考官方文件中的範例,分別計算兩個list中的文本,兩兩一組的相似度。整段程式碼的概念就是先用模型產生句子的embedding,再將embedding作為表徵來計算與其他句子間的相似度。

首次讀取模型時,會需要下載模型檔案。

執行後,我們將得到兩個句子間的相似度。其中計算相似度的方式為cosine similarity,是常見計算相似度的方式,相似度越接近1代表越相近。
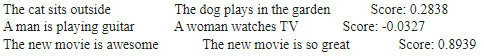
文本相似度應用-文章主題
當我們可以計算文本的相似度,我們可以很簡單的計算文章與主題分類的相似度,下面我們使用Multi-Lingual Model(多語言模型)中,支援中文的distiluse-base-multilingual-cased-v1來進行示範。
以下的範例我們將新聞的標題與類別分別文章主題計算相似度,在不對模型做任何調整的狀況下,可以看到即便標題中並未提到與分類相同的關鍵字,模型依然能與應該對應的類別輸出高於其他類別的分數。

文本相似度應用-意圖理解
相似度的概念也可以利用在意圖理解上。這邊參考國家發展委員會陳嘉浩分析師的實驗,在不做任何模型調整的狀況下,嘗試模型對問題的意圖理解判斷。在這邊也可以看到,將相似度進行排序後,可以看到分數最高的都有對應到正確的問題需求。
測試問句:您好,拿到新申請的憑證後,接下來要怎麼處理?
模型計算相似度最高結果:申請新卡後問題

測試問句:我拿我的憑證要登入我的網站可是一直進不去
模型計算相似度最高結果:無法開啟網頁
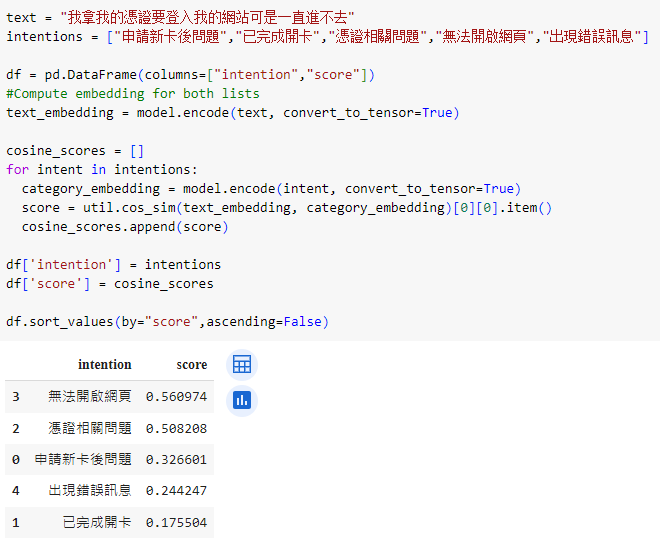
測試問句:我剛登入系統後發現我的憑證過期了請問怎麼辦
模型計算相似度最高結果:憑證相關問題

文本相似度應用-文本檢索
相似度的概念也可以應用在文本檢索,根據輸入的詞彙,搜尋帶有相關資訊的文本。例如,我們可以在以下的包含文章的內文和標題的資料中檢索資訊。

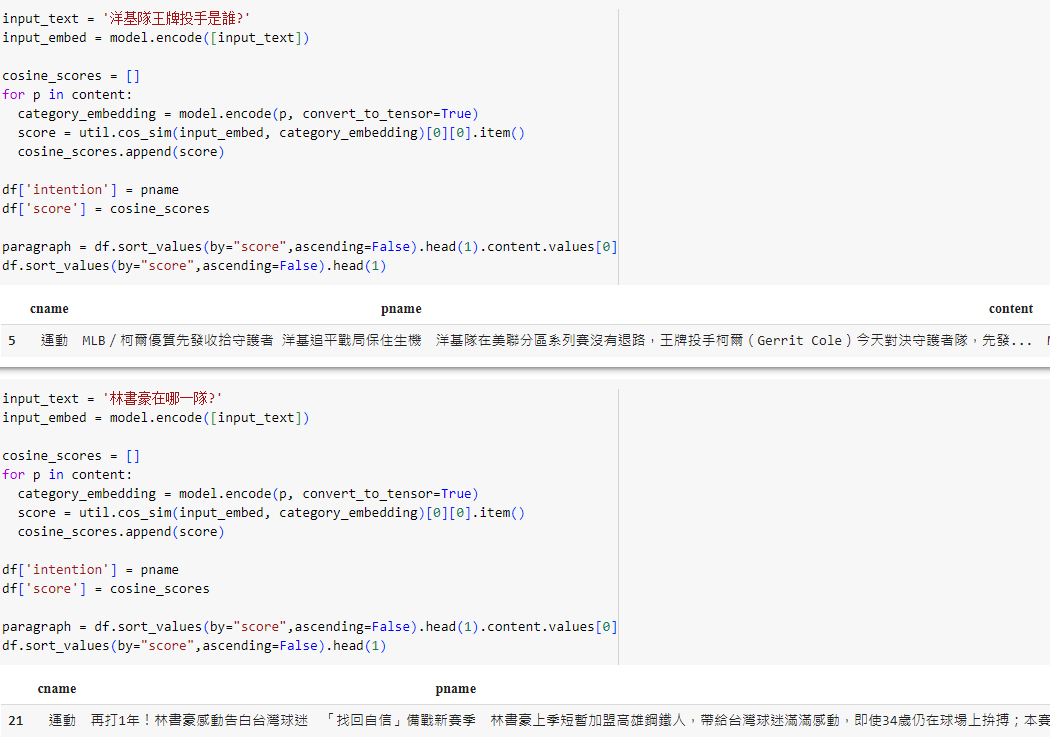
在下圖中,分別提問了 "洋基隊的王牌投手是誰?" 和"林書豪在哪一隊?"
我們可以利用相似度去搜尋相關資訊,列出相似度最高的文章來看是否包含相關的資訊。
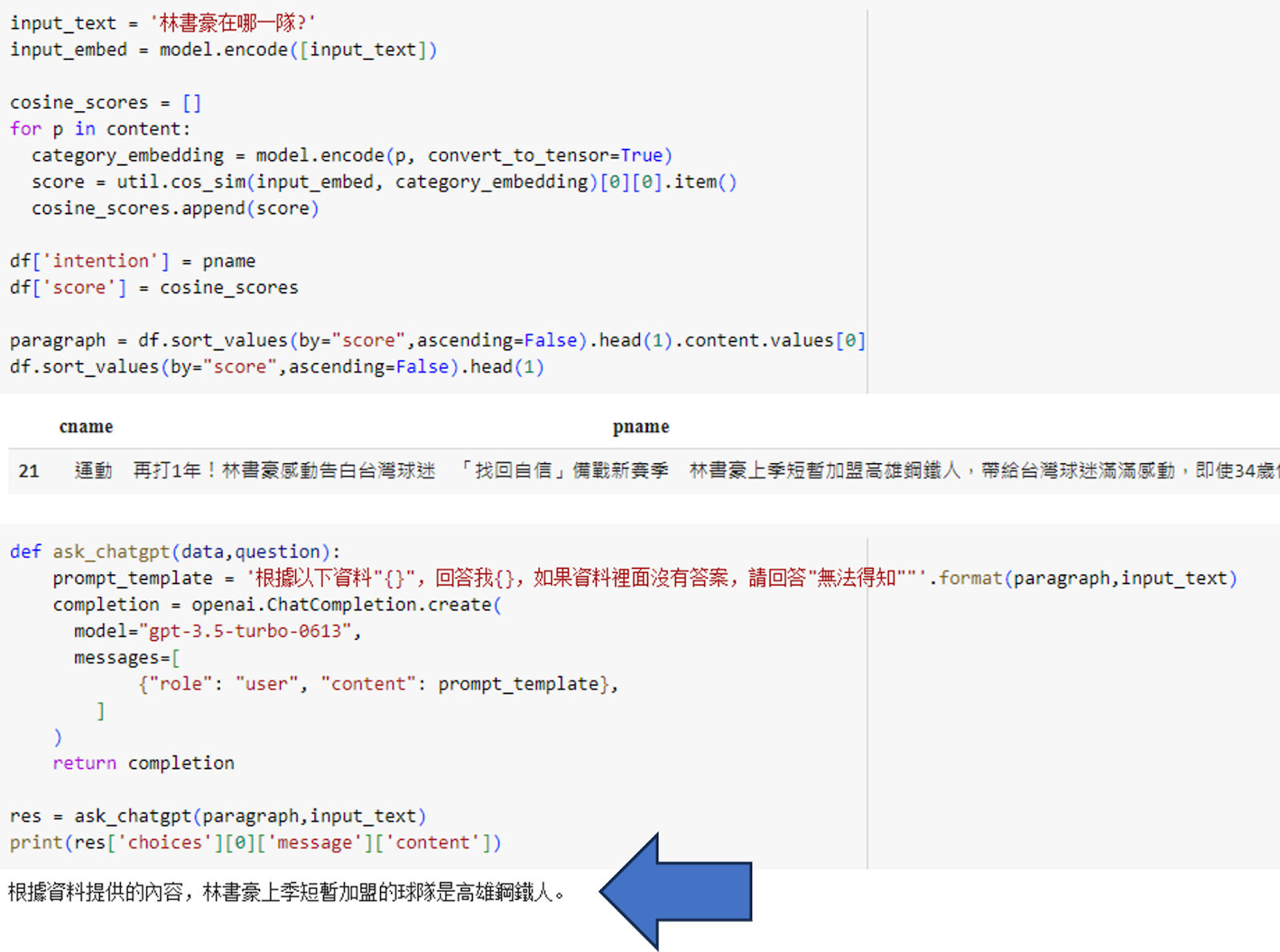
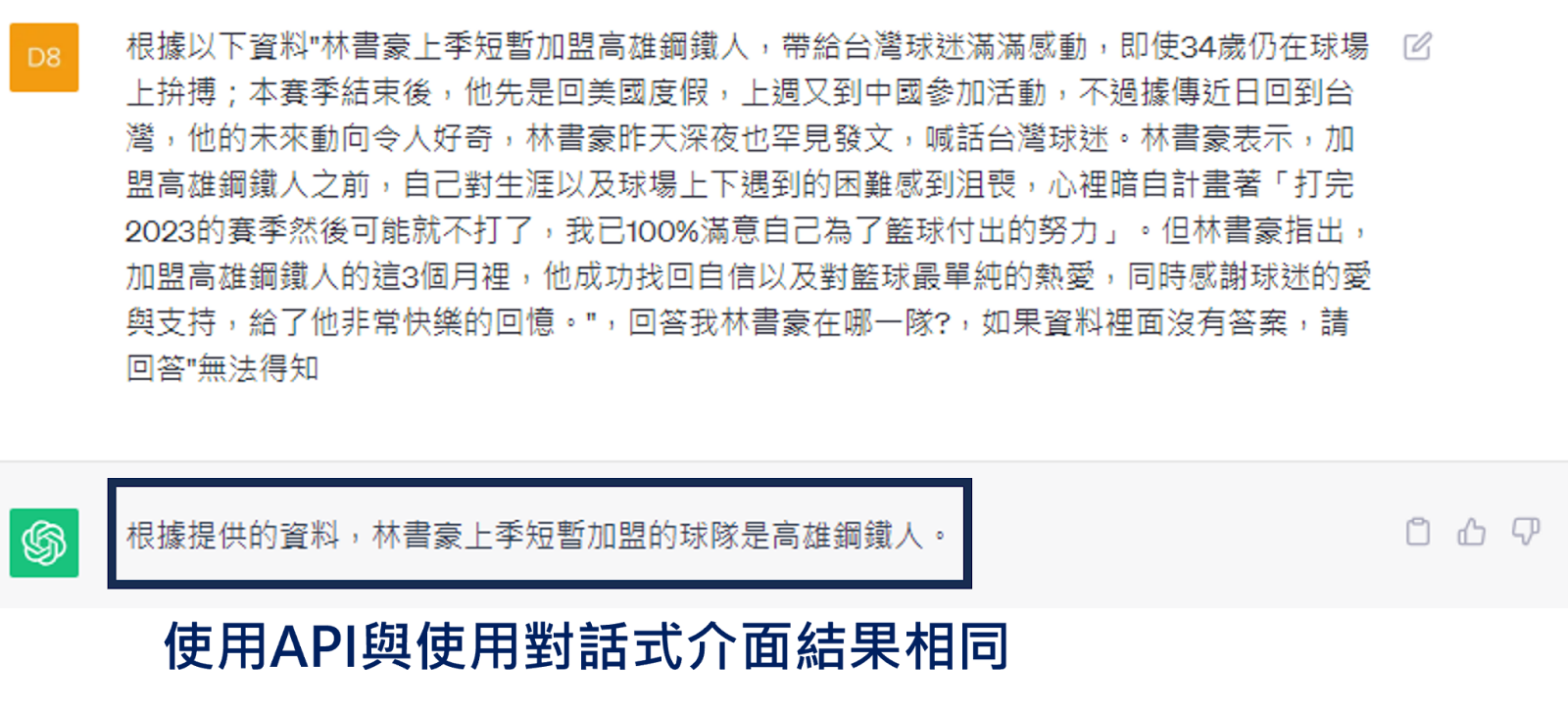
有了相關資訊,我們還能更進一步串接ChatGPT API,將文章作為參考資訊提供。如果直接提問,受限於資料的時間,ChatGPT可能無法回答即時的資訊。

然而,如果我們用剛剛檢索到的相關文章作為補充資訊,再向ChatGPT提問,就可以藉由較新的資訊,得到不同的回答。下圖中,藍色箭頭顯示的是使用ChatGPT API呼叫的結果,而在ChatGPT介面增加參考新資訊後也可以得到同樣的回答。
小結
本篇文章延續上篇的內容,利用實作帶大家嘗試簡單的使用模型產生Embedding與相似度計算,並且舉了幾個實際應用的情境來Demo效果。
然而,相信好學的你在看完這邊文章後,可能會有以下疑問:
- 為什麼預訓練的模型可以使用,他的核心概念是什麼?
- BERT和GPT的差異是什麼?
- 雖然預訓練的模型有一定效果,但是感覺效果好像還不夠好,有可能再調整嗎?
- 利用模型產生的Embedding,如果每次都要重新計算感覺很浪費資源,如何儲存比較適當?
- 相似度的計算在需要大量比對時,可能會非常耗時或需要很多運算資源,有沒有其他方式來實作?
以上這些問題,包含了預訓練、語言模型的歷史與差異、微調(fine-tune)、讓LLM利用自己資料來生成的 Retrieval Augmented Generation (RAG) 等這些重要概念,同時也包含要將這些模型落地應用,不可忽略考量的儲存、運算資源與效能問題。這些相關的內容都會在接下來的系列文章中跟大家一起討論,敬請期待。


