
[Data Science] ChatGPT 帶來崛起的向量資料庫 ! Embedding和向量資料庫系列-3:認識語言模型
前言
上回,我們在Embedding和向量資料庫系列-2:Embedding實作與相似度計算?介紹了如何實作文本生成Embedding的方式,以及幾個相似度計算的應用範例來給大家一些在用法上的想像。同時在上回的小結中還提到了幾個疑問,這些疑問其實就是我們今天要討論的主題,該如何來認識與理解語言模型。今天,在本篇文章中,我們將用簡單易懂的方式,從目標問題的不同來帶大家認識語言模型是如何設計和訓練的。
語言模型是怎麼訓練的?
在Embedding和向量資料庫系列-1:Embedding是什麼?中我們知道了Embedding是模型理解世界的方式,它可以將我們的輸入資訊經過一系列的訓練計算,找到可以表達實體資訊的向量。在語言模型的例子中,輸入的就會是我們平常說的自然語言,而Embedding就是模型用來理解表達的方式。
這個時候,相信大家可能會問,那模型怎麼知道要怎麼學習來理解自然語言呢?
首先,讓我們先來看看下面這張圖:

從圖可以很簡單的理解,我們輸入給模型一些資訊,然後希望模型經過計算後,提供給我們一個我們想要的輸出。模型就像一個魔法黑盒子,也像一個計算超級複雜的函式。
然而,模型再怎麼神奇,也都得有個定義好的輸入和輸出,才有辦法讓模型學習這之間的關係。因此,訓練模型的第一步就是: 定義好訓練目標。
常見的訓練目標,比如預測數值可以是利用消費紀錄預測消費金額,利用歷史股價預測未來股價。或是像分類問題可以是給定圖片分類貓狗,利用顧客消費紀錄分類顧客會不會購買新品。上述的例子都算是常見好理解的。然而,語言模型的訓練目標可能就比較難想像了,大家可以想想,怎樣算是有學懂語言呢? 其實大家可以想想英文考卷上會有什麼題目?像是克漏字、翻譯、閱讀測驗、寫作等...。其實這些都可能是我們認為可以學懂語言的練習方式,或許都可以用在訓練模型上。而在近代語言發展的歷史上,就有兩個流派分別用"文字填空"和"文字接龍"來做為模型訓練的目標取得了不錯的效果,他們就是大名鼎鼎的BERT和GPT模型。不過,在看BERT和GPT模型之前,我們必須先來了解這兩個模型的基礎,Transformer。
Transformer
Transformer模型是Google在2017年 Attention is all you need論文中發表的模型。
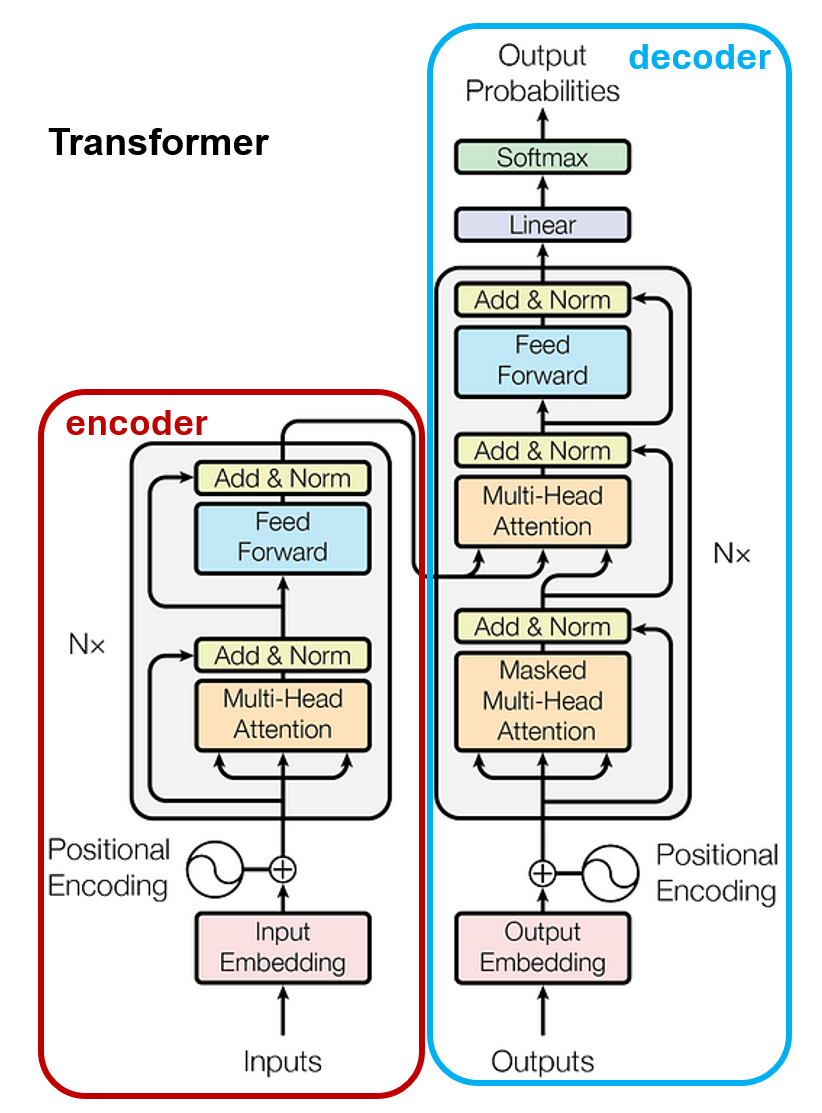
這邊我們不講太多深入的細節,有興趣的朋友可以去參考李宏毅老師的教學影片,影片講解得非常詳細。這邊就講幾個重點。Transformer是一個Sequence to sequence(Seq2seq)的模型,一個sequence可以是一段文字或是一段音頻。Transformer是由encoder(編碼器)和decoder(解碼器)組合而成的,其中使用到了Multi-head self-attention(多頭自注意力機制)。encoder可以理解成把輸入的東西編碼成一堆數字組成的向量,而decoder則可以想像成把這些人類看不懂的向量再轉換成人類想要的樣子,而Multi-head self-attention做的事情則是將序列中兩兩間的重要性權重計算出來,以利放大序列中的重要資訊。講的簡單一點,如果今天我們想要Transformer可以讓我們輸入中文句子,然後輸出英文句子,encoder做的就是將中文句子轉換成一些向量,而decoder則是將這些向量再轉換成英文的句子,其中Multi-head self-attention扮演的關鍵角色就是讓找出句中字詞間的語意關係、位置關係等。
BERT - 文字填空
BERT的架構是取用了Transformer中的encoder。主要的訓練方式是利用隨機遮蓋住字詞,並讓模型去找出合適的字詞去填空。如下圖所示:
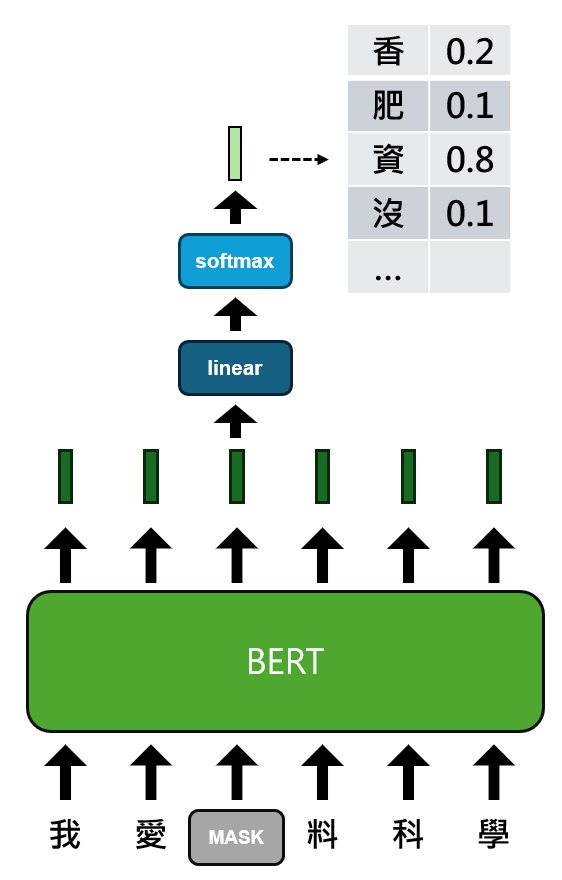
從上圖來看,BERT會經過這樣大量隨機被遮蓋字詞的文本,來學習語句文字間的關係,其中encode架構中的attention機制是雙向的,也就是這些字詞兩兩可以計算獲得彼此的資訊。
此外,其實BERT在訓練的過程中,也有進行Next Sentence Prediction的訓練任務,也就是給兩個隨機句子,輸出這兩句是否是接在一起的句子,不過這項訓練任務並沒有為BERT帶來太多的幫助。
而BERT我們通常的用法是,會針對不同的下游任務,再去做微調(fine-tune)。這也可以很簡單的理解,畢竟文字填空這項任務比較少在現實中應用,不過既然BERT可以很好的學習這些語意的關係,我們只要抽換最後幾層計算,並利用不同形式的資料集,比如翻譯、情感分析、文本分類、相似度計算等,就這樣在基於訓練好的BERT上,再用這些標註好的訓練集訓練,這就是微調(fine-tune)。
而我們前面一直提到的Embedding,其實就是這邊BERT學出來的向量,根據不同任務的微調,我們可以得到不同的Embedding表示。在chatGPT橫空出世之前,BERT這樣預訓練+微調的方式,一直是更廣為使用的作法,也衍生了各種不同的變種模型。
GPT - 文字接龍
GPT則走向跟BERT相反的路,GPT使用的是Transformer中的decoder,其架構中的attention機制是單向的,因為除了被預測的字詞以前的字,剩下往後的所有字都不應該被看到。訓練的方式就是蓋住後面的字,並訓練它可以預測下一個字詞是什麼,然後再一個接一個預測下去。
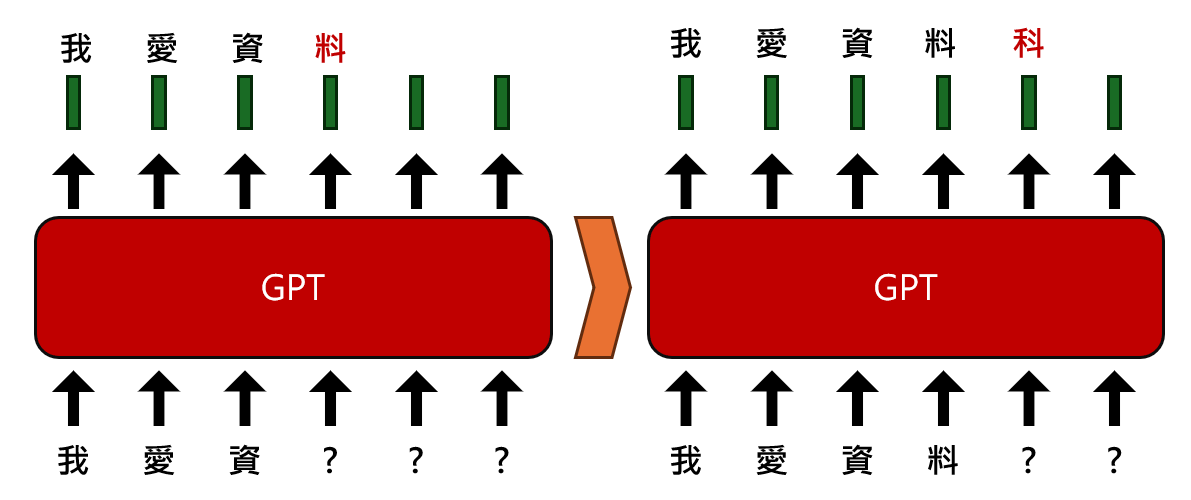
GPT藉由遮蓋某個字詞後面所有字詞,訓練它預測下個字詞能力,而他的資料來源就是大量網路上的語料,所以與其說GPT模型能夠聽懂我們的問題,不如說他很能知道一段問題後面應該接的是一段相關的答案。GPT系列的模型,一直到GPT-3使用極大量的文本進行訓練以後,才有了突破性的效果。
聽完上述兩個模型的介紹,相信好奇的你一定會想問說,有沒有encoder和decoder都用的語言模型,答案是 : 當然有 ! 像是Google 的 T5,huggingface的T0等。不過今天我們先不多做介紹了。
預訓練
上述我們介紹的兩個模型其實都包含了一個很重要的概念 : 預訓練。
如果對機器學習有概念的朋友,應該知道我們最常見的訓練方式是監督式學習,也就是在訓練之前,處理或取得標記好"答案"的資料,並且在訓練時告訴模型它輸出的跟答案差距多少,並讓它修正,就這樣重複直到適當的時機才停下。然而,語言的情境千遍萬化,我們很難窮舉出所有的情境。於是上述兩種模型都採用大量網路上的文本,一個隨機遮蓋,一個逐字預測,這兩種不需要特別標記好的訓練方式,就是自監督式學習(self-supervised learning)。而這些經由自監督式學習後的模型,又被稱為預訓練模型(pre-trained model)或是基礎模型(foundation model)。
而預訓練之所以可用,就是因為它經過了非常大量的語料進行訓練,將複雜的語意關係學習起來,接下來只要針對不同的任務在進行微調的"特訓",就可以達到很好的效果。
小結
本篇文章主要簡單介紹了近年來兩大熱門類型的大型語言模型的基礎模型跟想法,帶大家理解這兩種模型是怎麼被設計和訓練的。其實大家在理解模型的時候,可以去思考,這些模型設計的架構,是不是跟真實世界的我們思考類似議題時有相似的感覺呢? 畢竟深度學習在設計模型時,本來就是試圖模仿人類思考時,大腦神經元訊號的傳遞。能理解這個概念,要看懂模型設計的架構或許就沒那麼難囉。
今天聊完了兩個重要的基礎模型,下回我們就來介紹幾個微調(fine-tune)的概念,以及檢索增強生成(Retrieval Augmented Generation ,RAG) 這些讓大型語言模型更能落地的方法吧。究竟能產生表達複雜語意關係的向量的BERT和很會說話接龍的GPT相遇後,可以產出什麼新奇的玩法,讓我們拭目以待。


