
[Data Science] 什麼是混淆矩陣 (Confusion Matrix) -模型評估指標
前言
在機器學習和統計學中,混淆矩陣是一種表示監督式學習模型預測結果的表格,特別適用於分類問題。混淆矩陣可以幫助我們了解模型在不同類別上的表現情況,進而評估模型的效能。
一、混淆矩陣的概念
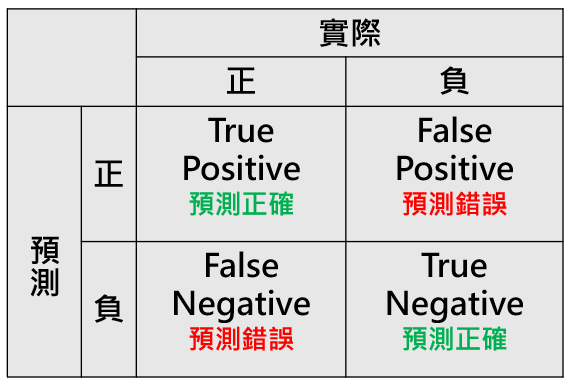
混淆矩陣通常是一個 N x N 的矩陣,其中 N 是類別的數量。對於二元分類問題來說,混淆矩陣是一個 2x2 的矩陣,包含以下四個重要的元素:
True Positive (TP):真陽性,表示模型正確地將正類別樣本分類為正類別。
False Positive (FP):假陽性,表示模型將負類別樣本錯誤地分類為正類別。
True Negative (TN):真陰性,表示模型正確地將負類別樣本分類為負類別。
False Negative (FN):假陰性,表示模型將正類別樣本錯誤地分類為負類別。
二、混淆矩陣的應用
混淆矩陣可以幫助我們計算出許多模型評估指標,包括準確率、精確率、召回率和 F值分數等。這些指標可以幫助我們全面評估模型在不同方面的表現。
準確率(Accuracy):模型正確預測的比例,計算公式為 (TP + TN) / (TP + TN + FP + FN)。
精確率(Precision):在模型預測為正類別的樣本中,真正為正類別的比例,計算公式為 TP / (TP + FP)。
召回率(Recall):在所有正類別樣本中,模型成功預測為正類別的比例,計算公式為 TP / (TP + FN)。
F值分數(F-score):精確率和召回率的加權調和平均數,計算公式:
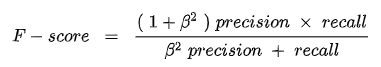
當Precision和Recall權重一樣時β=1,稱為F1-Score,代表同樣的注重這兩個指標。
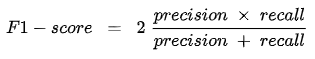
三、指標應用範例
假設我們建立了一個模型,希望可以預測電子郵件是否為垃圾郵件,模型預測了1000封郵件,其中有100封實際為垃圾郵件,將模型預測結果填入混淆矩陣後如下表,分別計算上面四個指標。
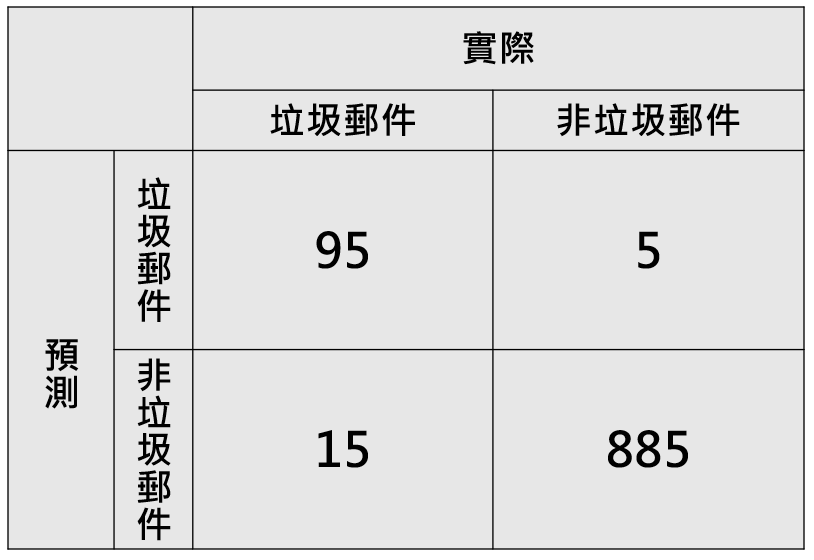
準確率(Accuracy)= (95+885) /1000 = 0.98
精確率(Precision)= 95 / (95+5) = 0.95
召回率 (Recall)= 95 / (95+15) = 0.864 (四捨五入到小數點第三位)
F1 - score = 2 (0.95*0.864) / (0.95+0.864)= 0.905 (四捨五入到小數點第三位)
四、指標使用情境
在一般的情況下,準確率可以表示一個模型的好壞,但如果在不平衡的資料集(正負樣本比例差異大)中,就無法只參考準確率,我們以剛剛的例子來舉例,模型若全部都猜非垃圾郵件,如下圖,這時候的準確率還有高達0.9。所以若資料不平恆的狀況越為嚴重,就越無法只參考準確率。
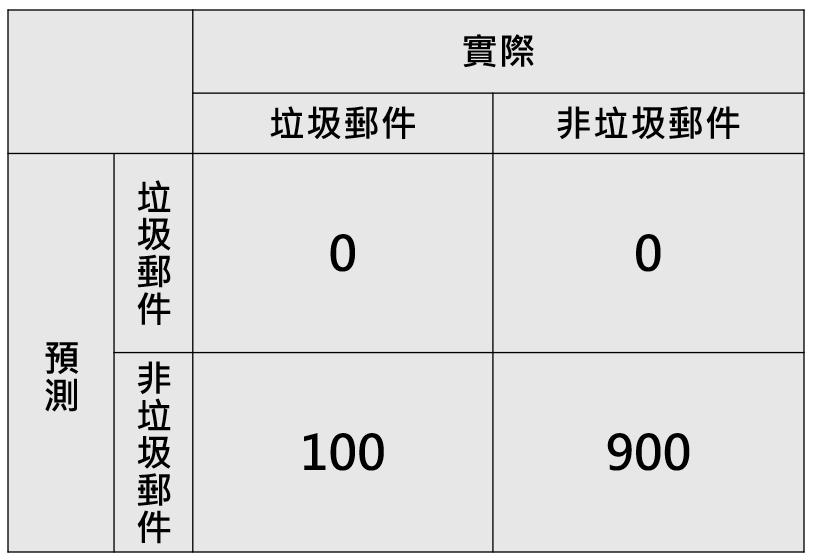
像是垃圾郵件、詐欺交易檢測、疾病預測,這些情況下都會是不平衡的資料集,但會因狀況的不同,關注精確率或召回率的程度也不同。像是在檢測詐欺交易的模型,會更關注召回率,希望可以最大可能性的抓到更多詐欺的交易。在疾病的預測,會更為關注精確率,避免對患者造成不必要的擔憂或治療。
五、結語
混淆矩陣是一個非常有用的工具,可以幫助我們評估機器學習模型在分類任務中的表現。通過混淆矩陣,我們可以了解模型在不同類別上的預測情況,進而針對模型的弱點進行改進,提高模型的性能。另外,面對不平衡資料集,除了從指標層面來改善衡量模型的方式,還有許多手段可以來處理不平衡的資料狀況,下回揭曉。


