
[Data Science] MLOps Python套件Scikit-Learn Pipeline
快速導覽


一、前言
機器學習已經成為推動業務創新和提升決策品質的重要力量。隨著機器學習模型在各行各業的廣泛應用,如何有效地將這些模型從實驗室環境轉移到生產環境,並確保它們在實際操作中的穩定性和效率,MLOps是一種實踐,結合了機器學習、DevOps(開發與運營)和數據工程的原則,旨在自動化和優化機器學習模型的整個生命周期。
二、Scikit-Learn介紹
是一種主要由python撰寫的套件庫,根據其官網的介紹:
- 用於分析、預測資料簡單且有效的工具
- 大部人都可以很快速上手,且可以適用於不同情境
- 基於NumPy, SciPy, and matplotlib建構
- 開源且商業可用
常見的分類、分群、迴歸等方法在scikit-learn中都可以找到,除了收納了多數常用模型外,也提供了不少除了模型以外的工具如:
- 資料預處理(標準化、遺失值處理...)
- 模型特徵選擇及降維(PCA、LDA)
- 模型評估方法(交叉驗證、Reacll、F1-score)
- 模型儲存
- 串起整套流程的管道功能Pipeline,組合成一個流程,這有助於簡化模型訓練和評估過程
這些工具的結合使用可以大幅提升機器學習項目的開發效率和模型的性能,這次主要闡述Pipeline的使用方式。
三、Scikit-Learn pipeline使用
1.載入套件
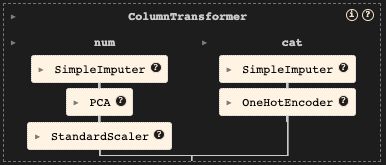
2. 建立Pipeline
設定資料預處理方式後若在juptyer上會有圖像化的方式流程
若只有一般的指令介面,也可以透過print(preprocessor.get_params())的方式來看內部有哪些設定


