
數據預測模型起手式:如何判斷品牌是否準備好了?
前情提要
之前的幾篇文章分享了預測模型的種類、限制和應用場景,除了實際運用的可能性與可用性外,大家最常問的問題還有:我們手上的數據是否足夠完成預測模型呢?實際上可否建置一個成功可用的預測模型,除了數據的多寡和品質外,也會受到應用範圍、更新頻率、產出標的和準確性要求等面向影響。但是!如果要把這些要素都評估完,不僅耗時還耗人力,今天想透過這篇文章的分享,讓非數據人員也可以快速完成初步判斷!帶著用這份守則評估的結果,再與數據團隊做更進一步的討論,相信可以有效加快您們的對焦速度唷~
哪些數據對建置預測模型來說是必要或需要的?
說好的5分鐘完成初判,絕對要讓您喝杯咖啡的時間就完成XD先提供完整大圖給各位,可以看到總共4種類(1-4)的數據判斷方向、並依狀況不同帶來4種結果(A-D):
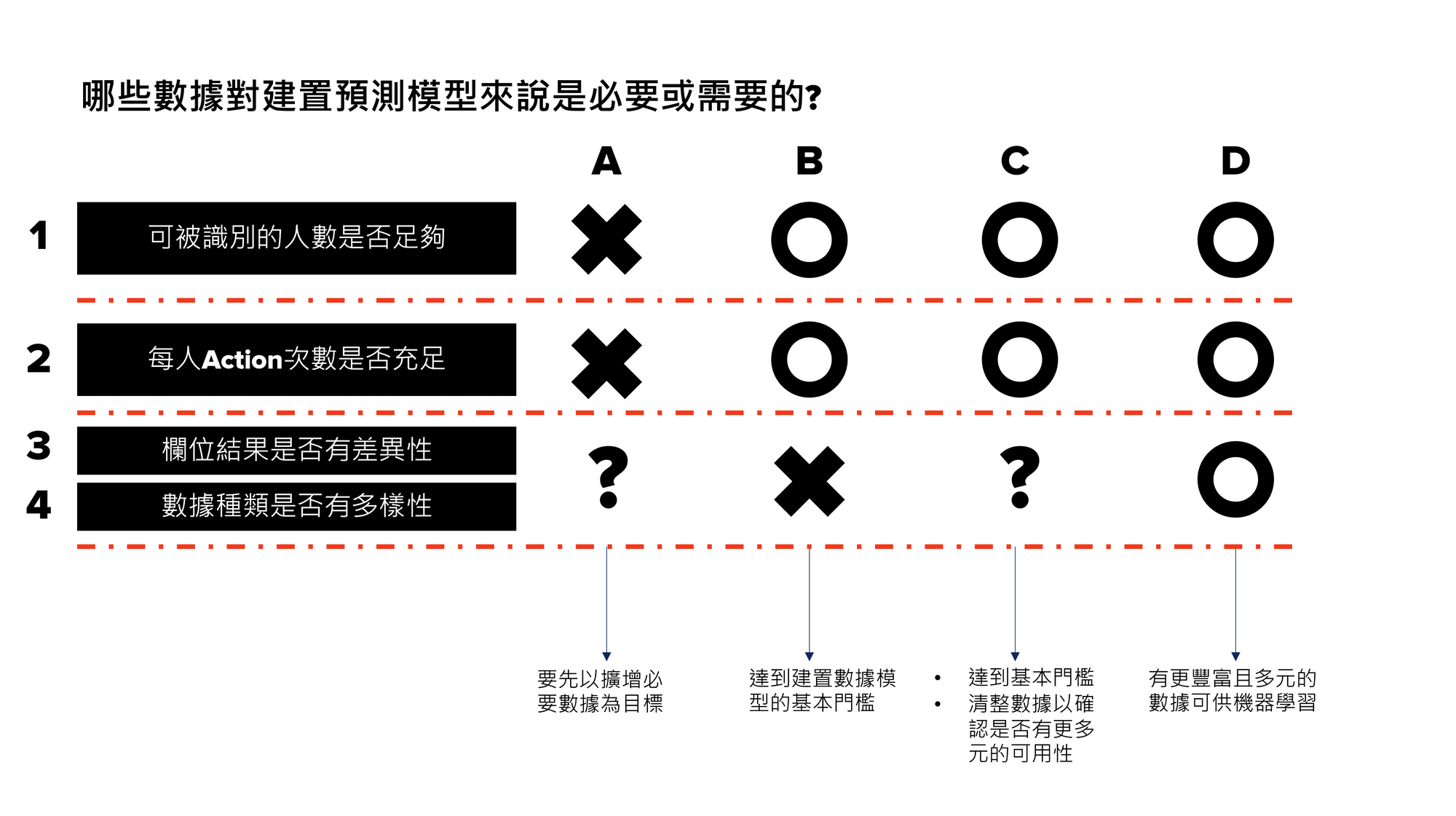
接下來逐步展開說明,首先是不同的數據判斷方向(1-4)
1. 可被識別的人數是否足夠:無論實名PII或匿名cookie,可以被視作「一個人」的量體是否足夠?而人數是否足夠,可以用下面兩個思路來初步判斷:
a.以後實際應用的量體是多少?假設每次投放廣告,大概都是10-15萬人
b.那麼從應用需要10-15萬人來回推,至少會希望有2倍=20-30萬的可識別人數
2. 每人Action次數是否充足:可被識別的這些人,是否都做過足夠多次我們想要預測的標的行為?舉例來說,我們想要預測回購機率,那麼這20-30萬人是否過去都曾經回購過多次?這個目的是讓機器學習到「回購」此行為跟個人以及其他資料的相關性。次數是否足夠會跟產業消費者的實際回購頻率有關,假設我們現在做的是美妝品的回購預測,消費者平均一年回購3次,那我們可以透過拉長資料取用的區間(從只抓近一年資料,延長到抓過去三年資料)的方式,讓每人的action次數較為充足。
3. 欄位結果是否有差異性:預測模型很重要的一點是讓機器分辨哪些是我們要的行為(比如回購),如果資料庫內所有人每個月都會回購,那對於機器來說反而失去鑑別的依據。部分人回購的同時有另一部分的人沒有回購,這樣的資料狀態會更有利於機器學習。
4. 數據種類是否有多樣性:預測模型最厲害的地方就在於能夠連結各種要素,計算出看似不相關的要素對標的行為的影響。交易是一種數據種類、demographic是一種數據種類、互動紀錄又是另一種數據種類。當數據種類越多,機器可以學習的方向就越多、也有機會更精準。
不同的數據持有狀況,各自帶來怎樣的預測模型建置可能?
理解完1-4不同的數據種類,我們再看一次這張圖,就可以更快的理解A-D 4種結果和對應的建議方向。
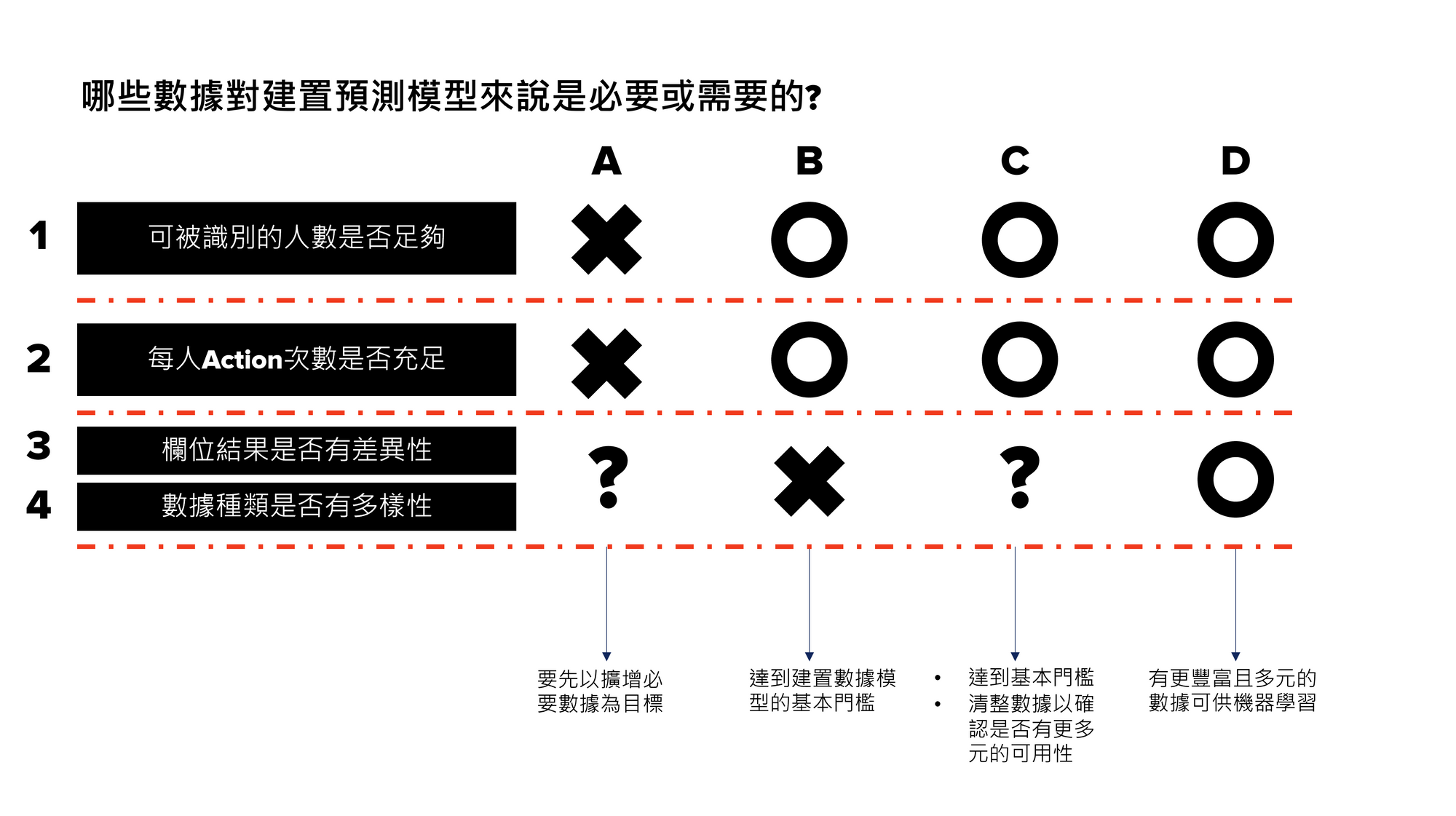
A:可識別人數不足 or 每人Action不充足
→→→建議先將人數和Action數擴充,再考慮建置預測模型
B:人數充足、Action充足;欄位差異性和數據種類多樣性不足
→→→可考慮建置預測模型(達到基本門檻)
C:人數充足、Action充足;欄位差異性和數據種類多樣性不確定
→→→可考慮建置預測模型(達到基本門檻),亦可先清整數據以期取得更豐富可用的資料源
D:人數充足、Action充足、欄位差異性大、數據種類多樣性高
→→→可考慮建置預測模型(數據豐富且多元,有利於機器學習)
從結果可以看出來,基本上人數和action數是很重要的先決條件、缺一不可。當這兩個條件都滿足,可以初步判斷已經具備建置預測模型的可能性囉,接下來就看是否有更多樣更豐富的資料可以讓機器學習的效果更上層樓。
看到這邊,您是否也對於自己品牌的預測模型建置可能性有個底了呢?若想了解更多預測模型的應用方向和使用場景,歡迎點擊作者頭像瀏覽其他相關文章!謝謝您今天的閱讀 :)


