
[Data Science] 想在自己電腦上玩大型語言模型? LM Studio的使用指南
前言
相信大家已經對 ChatGPT、Claude、Gemini、Perplexity 等大型語言模型不陌生,已經有過很多使用經驗。但慢慢地,你可能開始會想,”我的資料很敏感,我不想要讓資料被這些模型利用來再訓練”。 或者,你可能想將LLM(大型語言模型)整合到自己的小應用,卻覺得一直付費打API不划算。 於是你開始思考,有沒有可能在自己的電腦上運行一個LLM服務呢? 但一想到環境設定就覺得頭大,不知從何下手。
別擔心,本文接下來要介紹的LM Studio能解決你的這些問題,不需要複雜的建置步驟,就能讓你輕鬆建立自己個LLM服務。想知道怎麼做到的嗎?接著看下去吧!
LM Studio
LM Studio 是一個提供圖形化介面的Desktop應用程式,讓使用者可以在本地電腦上運行與實驗各種開源LLM。
根據官方文件,它主要有幾個功能:
- 在本地端運行LLM
- 大家都熟悉的對話介面
- 可以直接搜尋並下載Hugging Face上的開源模型來使用
- 可以運行一個跟Open AI API類似的 local server來提供服務
- 管理電腦上的模型與配置
看起很方便對吧? 不過,在我們開始前有兩件事情必須先釐清:
- 雖然目前LM Studio可以免費讓大家下載用於個人使用,但它並非完全開源,它並沒有將前端介面原始碼開源出來。雖然對於一般人使用並沒有太大影響,但如果真的很擔心,可以參考其他的開源介面(LobeChat、、LibreChat 、Open WebUI等開源專案)。
- LM Studio 並非從無到有"訓練一個新的模型",也不能”Fine-tune”一個模型,以上的運作和應用都是基於”開源”的語言模型。所以你不能用它訓練、微調一個新模型,也不能使用閉源、付費的LLM模型(如:GPT-4o)。

LM Studio
直接在官網首頁可以找到安裝包的下載選項,可以發現它支援跨平台的作業系統。這邊可以直接選擇對應的作業系統來下載安裝。而在官方文件的最低建議規格中,主要是建議使用者至少有16GB以上的RAM,原因在於LLM會需要大量的RAM。值得注意的是,這裡並沒有提到GPU(顯卡)是必須的,也就是說即使你沒有GPU,也能用CPU去運行。當然,相比於GPU,CPU的執行速度一定是比較慢的。不過在這裡,不論你有無GPU,都可以直接下載安裝,安裝包會自動針對硬體規格去安裝,接下來的示範也會以有GPU的狀況來介紹。
介面介紹
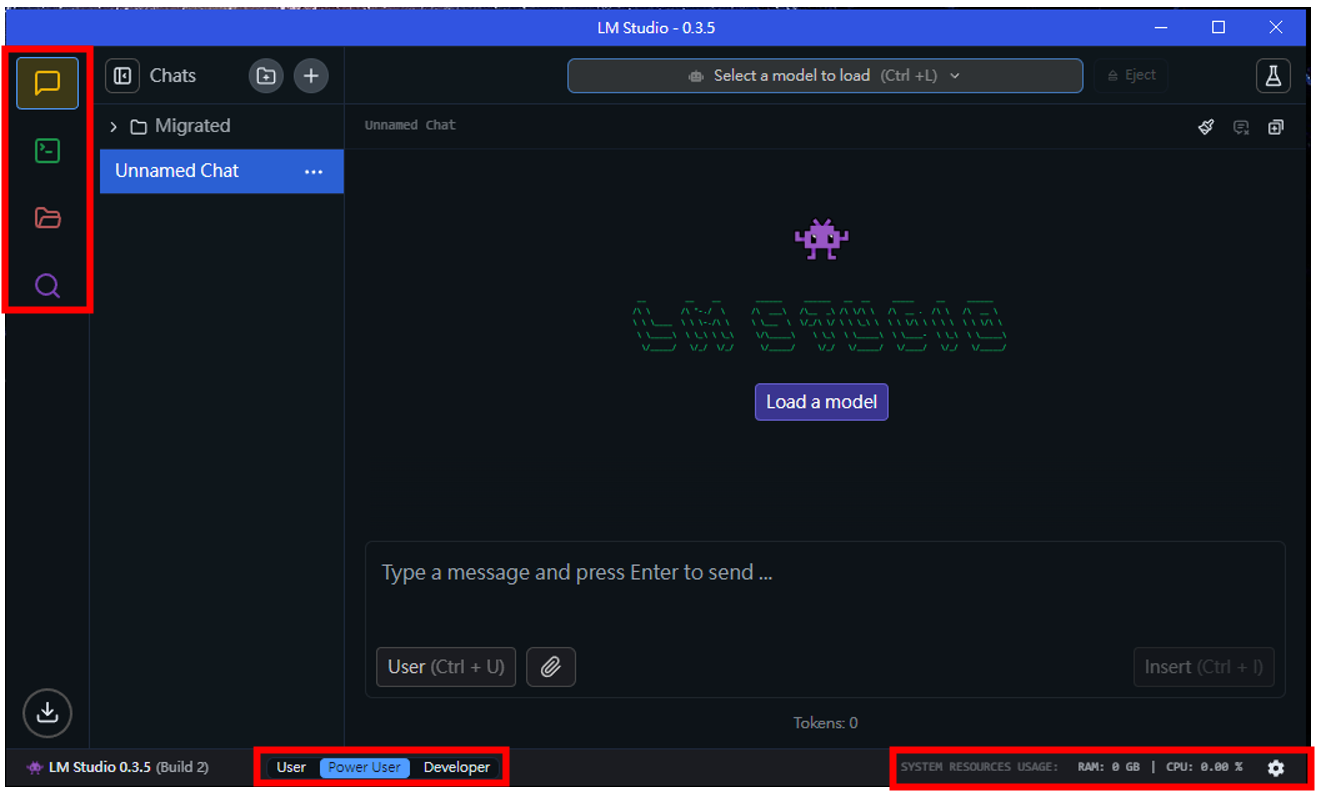
相較於過往的0.2版本,目前的0.3.5版本介面設計得更簡潔,在左下角選擇”Power User”模式後(預設),就可以看到主要提供的四個功能集中在左上角,由上到下分別為: Chat(對話)、Developer(主要是Server)、My Models(模型管理)、Discover(查找模型)。
而右下角的顯示當前資源的使用率,包含RAM和CPU的用量。

點選右下角的齒輪,可以檢查更新、更改語言,UI風格等,其中值得一提的是,讀取設定模型的資源限制程度(Model Loading Guardrails),可以利用不同程度的限制來避免過載。另外也提供headless來讓LLM server可以在背景執行的選項,一旦勾選,即使視窗關閉LLM server仍會繼續執行。
功能介紹 - Discover
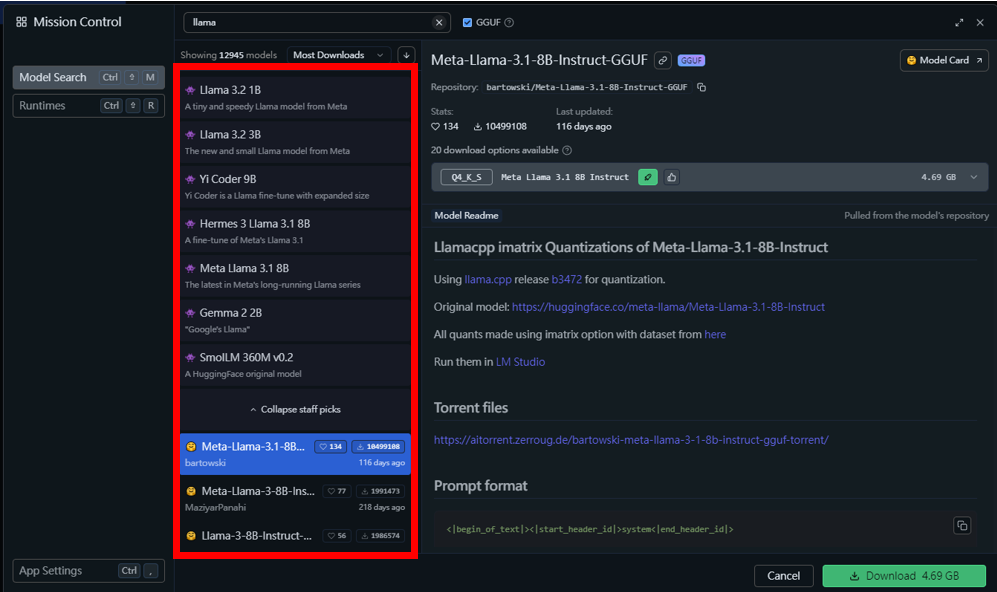
Discover的功能主要是讓使用者可以在搜尋想要下載的模型,可以看到有LM Studio Community和其他人貢獻在Huggingface社群的模型。其中,在模型命名中會看到3B、9B等數字,B 是十億(billion),用來表示模型的參數數量。通常相同系列的模型,參數數量越多,效能越強,但需要的運算資源,記憶體也會越大。
相信細心的你肯定會好奇下載下來的檔案是什麼?為什麼一個模型會有很多不同的版本可以供下載? 這裡就得來討論GGUF和Quantization(量化)是什麼。
什麼是GGUF ?
GGUF(GPT-Generated Unified Format) 是一種由Georgi Gerganov發布的文件格式,將模型的巨大檔案轉換為GGUF格式後,大型語言模型可以更好的被儲存與交換。同時藉由這樣的轉換,可以讓模型的讀取更快、使用更少資源就能運作。 (詳細的發展歷史與技術細節礙於篇幅,本篇文章暫時不討論)
什麼是Quantization(量化)?
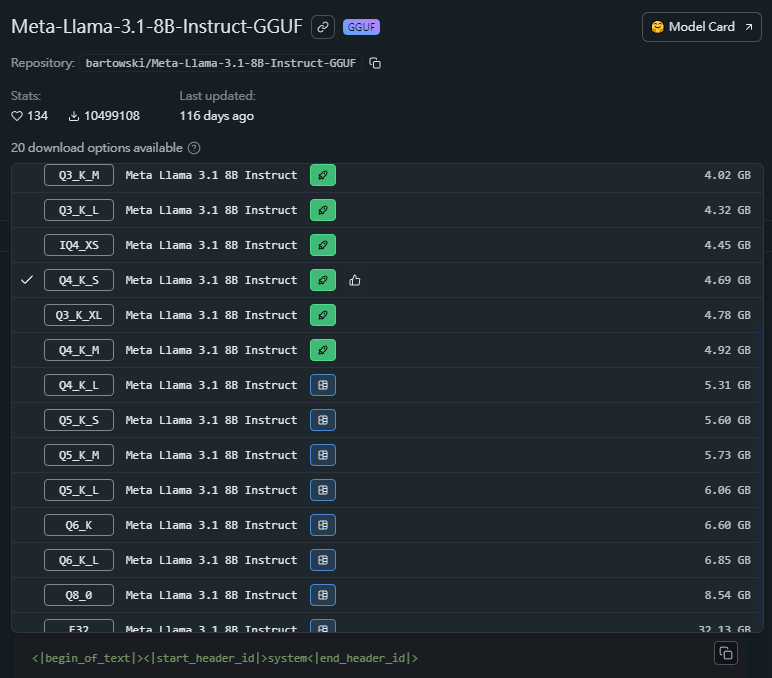
從上面的圖片中,可以看到都一樣都是Llama 3 8B,為什麼會有不同大小的檔案? 其實差別就在於量化方式與程度的不同。基本上檔案越大,模型效能越好。而最左方的命名就表示了量化的相關資訊。
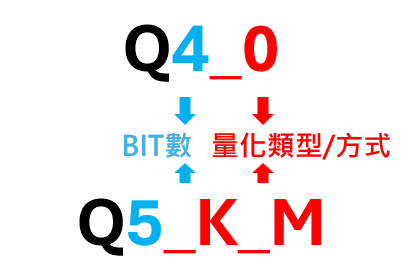
在量化的格式中,前面的數字代表BIT數,主要跟精度有關,數字越大模型越大,效果更好但也需要更多運算資源。後面的字符代表量化的類型與方式,簡單的介紹如下:
- _0(type 0 )、_1(type 1) : 權重由不同的方法產出,是最基本的類型。
- _K_L、_K_M、_K_S : K代表 k-quant,後面的L、M、S表示使用高精度的不同比例,L在部分張量使用更高精度,M則在部分張量使用次高精度,S則是全部都保持在同樣精度。
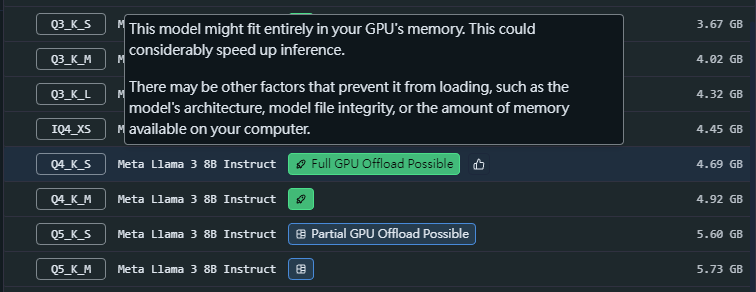
基本上在量化的命名上,前面的數字越大模型越強,量化格式的效果依序是K_L>K_M>K_S。如果不確定目前的硬體可以跑怎樣的模型,LM Studio也提供建議,顯示”Full GPU Offload Possible”,指的就是評估可以完全load進GPU執行,反之則可能遇到OOM(Out of memory)的問題。在預設的情況下,LM Studio會下載評估可運行的選項中,模型最大最佳的版本。
功能介紹 - My Models
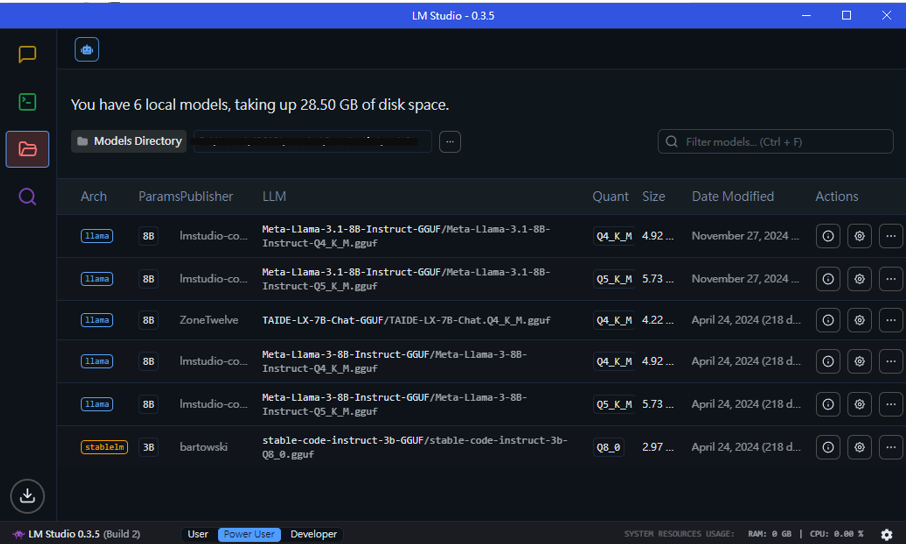
模型管理的介面就非常單純,可以看到已經下載的模型的詳細資訊,如大小、參數量等資訊。
功能介紹 - Chats
對話的介面就跟平常在使用ChatGPT類似,可以在選擇模型後,在下方文字框輸入訊息,也可以透過附加檔案的方式,實現類似RAG的功能。
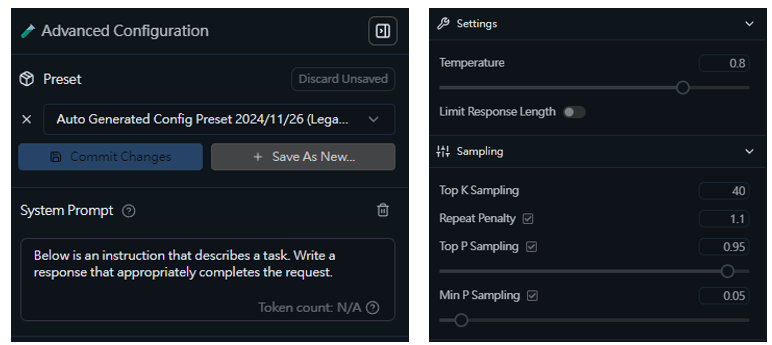
點開對話框右上角的進階設定,還可以設定System Prompt,讓模型代入一些固定的concept來產生輸出。也可以透過調整Temperature或Sampling來增加輸出文本的”創造力”。
功能介紹 - Developer
在Developer的功能中,主要可以將你選擇的LLM作為Server的形式運行,透過與OpenAI API相似的方式呼叫,取得對話或Embedding的功能。
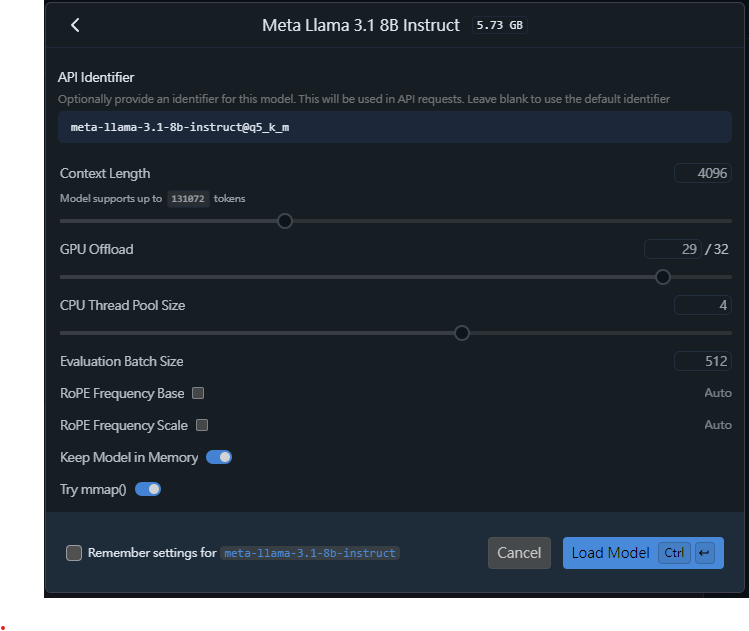
載入模型時,可以設定限制輸入的token數,載入GPU的層數,CPU 線程數等,調配運算資源來運行Local LLM Server。
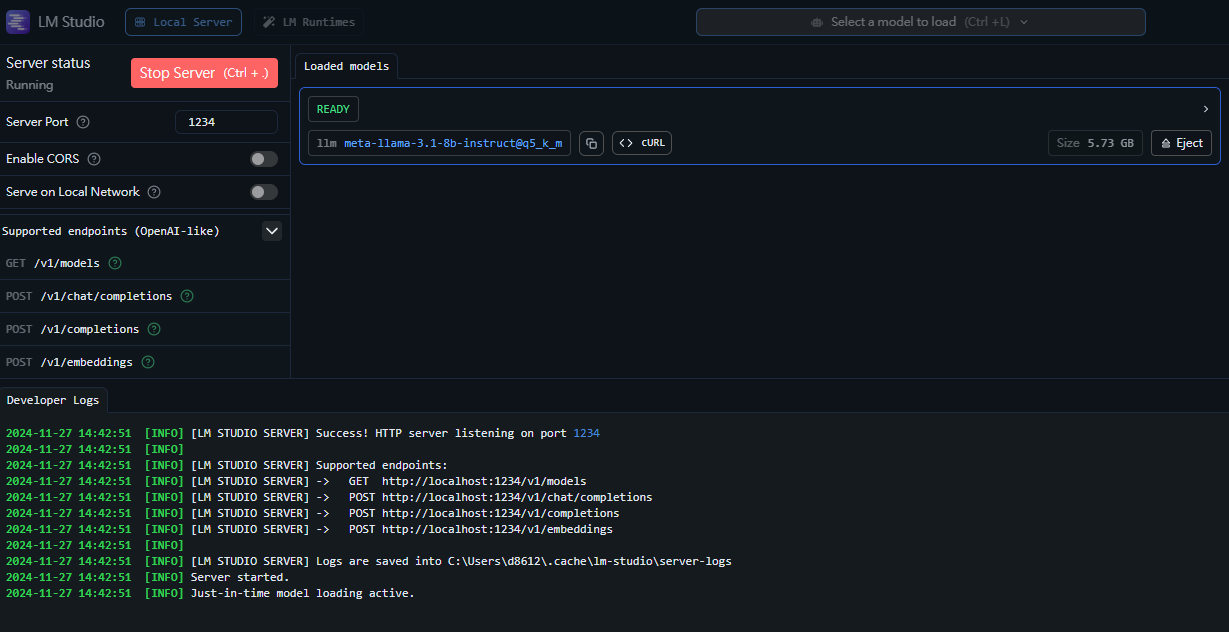
按下Start Server運行起來後,就可以透過API的方式去做呼叫,可以很簡單的去做後續的應用或實驗等嘗試。
小結
LM Studio 為想要探索大型語言模型但又不熟悉技術細節的人提供了一個簡單、高效的解決方案。不需要花費高昂的成本與時間,你可以輕鬆地在自己的電腦上運行開源模型,進行實驗與測試,並且避免資料外流的風險。透過 LM Studio,你可以在完全離線的環境下享受 LLM 的強大功能,無論是測試新模型、整合應用,還是打造專屬的 AI 對話系統,都能得心應手。趕快去動手試試看吧~


